"جنگو چیست؟" Django
جنگو یک فرم ورک وب سطح بالا پایتون است که توسعه سریع وب سایت های امن و قابل نگهداری را امکان پذیر می کند. بسیاری از دردسرهای توسعه وب را برطرف می کند، بنابراین می توانید بدون نیاز به اختراع مجدد چرخ، روی نوشتن برنامه خود تمرکز کنید. جنگو رایگان و منبع باز است.
جنگو به شما کمک می کند تا نرم افزارهایی بنویسید که عبارتند از:
جنگو میتواند برای ساختن تقریباً هر نوع وبسایتی (از سیستمهای مدیریت محتوا و ویکیها گرفته تا شبکههای اجتماعی و سایتهای خبری) استفاده شود. جنگو به طور پیش فرض محافظت در برابر بسیاری از آسیب پذیری ها، از جمله تزریق SQL، اسکریپت بین سایتی، جعل درخواست بین سایتی و کلیک جک را امکان پذیر می کند.
جنگو از یک معماری مبتنی بر کامپوننت است.جنگو به زبان پایتون نوشته شده است که روی پلتفرم های زیادی اجرا می شود. این بدان معناست که شما به هیچ پلتفرم سرور خاصی وابسته نیستید و میتوانید برنامههای خود را روی بسیاری از نخه های لینوکس، ویندوز و macOS اجرا کنید.
کد جنگو چه شکلی است؟
هنگامی که درخواستی دریافت میشود، برنامه بر اساس URL و احتمالاً اطلاعات موجود در دادههای POST یا دادههای GET، موارد مورد نیاز را بررسی میکند. بسته به آنچه مورد نیاز است، ممکن است اطلاعات را از یک پایگاه داده بخواند یا بنویسد یا سایر وظایف مورد نیاز برای برآورده کردن درخواست را انجام دهد. سپس برنامه پاسخی را به مرورگر وب برمیگرداند، و اغلب به صورت پویا یک صفحه HTML برای مرورگر ایجاد میکند تا با قرار دادن دادههای بازیابی شده در محلهایی در قالب HTML نمایش داده شود.
برنامه های تحت وب جنگو معمولا کدهایی را که هر یک از این مراحل را انجام می دهد در فایل های جداگانه گروه بندی می کنند:
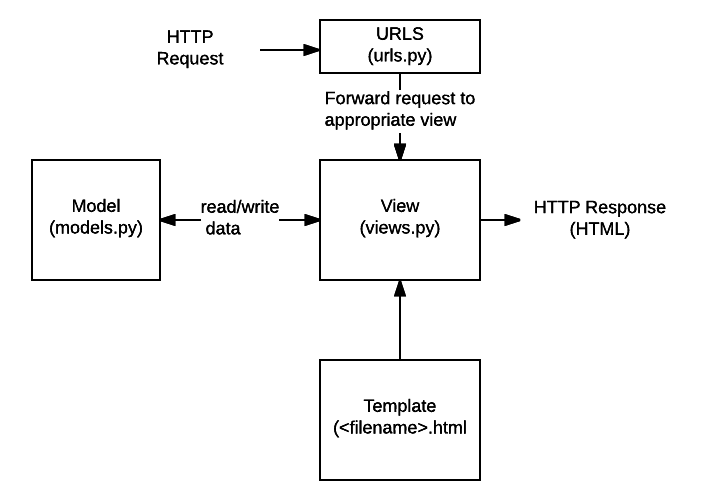
URL ها: URL برای هدایت درخواستهای HTTP به View مناسب بر اساس URL درخواست شده استفاده میشود. آدرس URL همچنین میتواند الگوهای خاصی از رشتهها یا ارقام را که در URL ظاهر میشوند مطابقت دهد و آنها را به عنوان داده به یک تابع view ارسال کند.
View: یک view یک تابع کنترل کننده درخواست است که درخواست های HTTP را دریافت می کند و پاسخ های HTTP را برمی گرداند.view ها به دادههای مورد نیاز برای برآورده کردن درخواستها از طریق مدلها دسترسی دارند و قالببندی پاسخ را به الگوها واگذار میکنند.
Model : مدلها اشیاء پایتون هستند که ساختار دادههای یک برنامه کاربردی را تعریف میکنند و مکانیسمهایی را برای مدیریت (افزودن، اصلاح، حذف) و پرس و جو رکوردها در پایگاه داده ارائه میکنند.
Template: الگو یک فایل متنی است که ساختار یا طرح بندی یک فایل (مانند صفحه HTML) را با متغیرهایی که برای نمایش محتوای واقعی استفاده می شود، تعریف می کند. یک view می تواند به صورت پویا یک صفحه HTML با استفاده از یک الگوی HTML ایجاد کند و آن را با داده های یک مدل پر کند. یک الگو می تواند برای تعریف ساختار هر نوع فایلی استفاده شود. لازم نیست HTML باشد!
توجه: جنگو از این سازماندهی به عنوان معماری "مدل نمای الگو (MVT)" یاد می کند. شباهت های زیادی به معماری آشناتر Model View Controller دارد.
بخشهای زیر به شما ایده میدهند که این بخشهای اصلی یک برنامه جنگو چگونه به نظر میرسند.
ارسال درخواست به نمای مناسب (urls.py)
یک URL mapper معمولاً در فایلی به نام urls.py ذخیره می شود. در مثال زیر، urlpatterns فهرستی از نگاشتها بین مسیرها (الگوهای URL خاص) و توابع نمای مربوطه را تعریف میکند. اگر یک درخواست HTTP دریافت شود که دارای URL منطبق با الگوی مشخص شده باشد، تابع view مربوطه فراخوانی شده و درخواست ارسال می شود.
urlpatterns = [
path('admin/', admin.site.urls),
path('book/int:id/', views.book_detail, name='book_detail'),
path('catalog/', include('catalog.urls')),
re_path(r'^([0-9]+)/$', views.best),
]
شی urlpatterns لیستی از توابع ()path و یا ()re_path است
اولین آرگومان برای هر دو روش یک مسیر (الگو) است که مطابقت خواهد داشت. متد ()path از پرانتز برای تعریف بخشهایی از URL استفاده میکند که به عنوان آرگومانهای نامگذاری شده است و به تابع view ارسال میشوند.
آرگومان دوم تابع دیگری است که با تطبیق الگو /book/int:id فراخوانی می شود. views.book_detail نشان می دهد که تابع ()book_detail اشاره می کند و می توان آن را در ماژولی به نام views (به عنوان مثال در داخل فایلی به نام views.py) پیدا کرد.
class BookDetailView(generic.DetailView):
"""Generic class-based detail view for a book."""
model = Book
تابع ()re_path از یک رویکرد تطبیق الگوی انعطاف پذیر استفاده می کند که به عنوان یک عبارت منظم شناخته می شود.
رسیدگی به درخواست (views.py)
viewها قلب برنامه وب هستند ، درخواستهای HTTP را از مشتریان وب دریافت میکنند
، درخواستهای HTTP را از مشتریان وب دریافت میکنند و پاسخهای HTTP را برمیگردانند
و پاسخهای HTTP را برمیگردانند . در این بین، آنها منابع دیگر فریم ورک را برای دسترسی به پایگاه داده ها، رندر قالب ها و غیره به کار می گیرند.
. در این بین، آنها منابع دیگر فریم ورک را برای دسترسی به پایگاه داده ها، رندر قالب ها و غیره به کار می گیرند.
مثال زیر یک تابع ()view minimal index را نشان میدهد که میتوانسته توسط URL mapper ما در بخش قبل فراخوانی شود. مانند تمام توابع view، یک شی HttpRequest را به عنوان پارامتر (درخواست) دریافت می کند و یک شی HttpResponse را برمی گرداند. در این مورد، ما هیچ کاری با درخواست انجام نمی دهیم، و پاسخ ما یک رشته کدگذاری شده را برمی گرداند.
# filename: views.py (Django view functions)
from django.http import HttpResponse
def index(request):
return HttpResponse('Hello from Django!')
ماژولهای پایتون «کتابخانههایی» از توابع هستند که در فایلهای جداگانه ذخیره میشوند و ممکن است بخواهیم از آنها در کد خود استفاده کنیم. در اینجا فقط شی HttpResponse را از ماژول django.http وارد می کنیم تا بتوانیم از آن در view خود استفاده کنیم:
from django.http import HttpResponse . راه های دیگری برای وارد کردن برخی یا همه اشیا از یک ماژول وجود دارد.
توابع با استفاده از کلمه کلیدی def همانطور که در بالا نشان داده شده است، با پارامترهای نامگذاری شده در داخل پرانتز بعد از نام تابع تعریف می شوند. آخر تابع به یک کولون ختم می شود. به نحوه تورفتگی خطوط بعدی توجه کنید. تورفتگی مهم است، زیرا مشخص میکند که خطوط کد در داخل آن بلوک خاص قرار دارند (تورفتگی اجباری یکی از ویژگیهای کلیدی پایتون است و یکی از دلایلی است که کد پایتون بسیار آسان است).
تعریف مدل های داده (models.py)
برنامه های تحت وب جنگو، داده ها را از طریق اشیاء پایتون که مدل نامیده می شوند، مدیریت و پرس و جو می کنند. مدلها ساختار دادههای ذخیرهشده را تعریف میکنند، از جمله انواع فیلدها و احتمالاً حداکثر اندازه، مقادیر پیشفرض، گزینههای فهرست انتخاب، متن راهنما برای مستندات، متن برچسب برای فرمها، و غیره. تعریف مدل مستقل از پایگاه داده زیربنایی است. هنگامی که انتخاب کردید از چه پایگاه داده ای می خواهید استفاده کنید، اصلاً نیازی به صحبت مستقیم با آن ندارید - فقط ساختار مدل و سایر کدهای خود را بنویسید، و جنگو تمام برقراری ارتباط با پایگاه داده را انجام می دهد.
قطعه کد زیر یک مدل جنگو بسیار ساده برای یک شی Team را نشان می دهد. کلاس Team از کلاس Django models.Model گرفته شده است. نام تیم و سطح تیم را به عنوان فیلدهای کاراکتر تعریف می کند و حداکثر تعداد کاراکترهایی را که برای هر رکورد ذخیره می شود، مشخص می کند. team_level می تواند یکی از چندین مقدار باشد، بنابراین ما آن را به عنوان یک فیلد انتخابی تعریف می کنیم و نقشه ای بین گزینه های نمایش داده شده و داده های ذخیره شده به همراه یک مقدار پیش فرض ارائه می دهیم.
# filename: models.py
from django.db import models
class Team(models.Model):
team_name = models.CharField(max_length=40)
TEAM_LEVELS = (
('U09', 'Under 09s'),
('U10', 'Under 10s'),
('U11', 'Under 11s'),
... #list other team levels
)
team_level = models.CharField(max_length=3, choices=TEAM_LEVELS, default='U11')
داده های پرس و جو (views.py) مدل جنگو یک API پرس و جو ساده برای جستجوی پایگاه داده مرتبط ارائه می دهد.
این می تواند با تعدادی از فیلدها در یک زمان با استفاده از معیارهای مختلف مطابقت داشته باشد (به عنوان مثال دقیق، حساس به حروف بزرگ، بزرگتر از، و غیره)، و می تواند از عبارات پیچیده پشتیبانی کند
خط list_teams = Team.objects.filter(team_level__exact="U09") نشان میدهد که چگونه میتوانیم از API query مدل برای فیلتر کردن همه رکوردهایی استفاده کنیم که فیلد team_level دقیقاً متن 'U09' دارد (توجه داشته باشید که چگونه این معیار به ()filter بهعنوان آرگومان عمل میکند، با نام فیلد و نوع تطبیق که با یک زیرخط دوتایی از هم جدا شدهاند: team_level__exact).
## filename: views.py
from django.shortcuts import render
from .models import Team
def index(request):
list_teams = Team.objects.filter(team_level__exact="U09")
context = {'youngest_teams': list_teams}
return render(request, '/best/index.html', context)
این تابع از تابع ()render برای ایجاد HttpResponse استفاده می کند که به مرورگر ارسال می شود. این تابع یک میانبر است.
یک فایل HTML با ترکیب یک الگوی HTML مشخص و برخی داده ها برای درج در قالب (در متغیری به نام "context" ارائه شده است) ایجاد می کند.
ارائه داده ها (الگوهای HTML)
سیستمهای الگو به شما امکان میدهند ساختار یک سند خروجی را با استفاده از نگهدارندههای مکان برای دادههایی که هنگام تولید صفحه پر میشوند، مشخص کنید. قالب ها اغلب برای ایجاد HTML استفاده می شوند، اما می توانند انواع دیگری از سند را نیز ایجاد کنند.
قطعه کد زیر نشان می دهد که الگوی HTML فراخوانی شده توسط تابع ()renderچگونه است. این الگو با این فرض نوشته شده است که وقتی رندر می شود به متغیر لیستی به نام Youngest_teams دسترسی خواهد داشت (این در متغیر متنی داخل تابع ()render بالا موجود است). در داخل اسکلت HTML یک عبارت داریم که ابتدا بررسی میکند که آیا متغیر youngest_teams وجود دارد یا خیر، و سپس آن را در یک حلقه for تکرار میکند. در هر تکرار، الگو مقدار team_name هر تیم را در عنصر
نشان میدهد.
return render(request, '/best/index.html', context)
## filename: best/templates/best/index.html
Home page
{% if youngest_teams %}
{% for team in youngest_teams %}
{% else %}
No teams are available.
{% endif %}
{{ team.team_name }}
{% endfor %}
خلاصه(ساده و روان):
جنگو فرم ورکی برای برنامه نویسان پایتون است تا بتواند با استفاده از آن به راحتی وب سایت خود را طراحی کنند. جنگو درخواست کاربر(Request) که همان آدرس URL است توسط فایلی به نام Urls.py که مسیر URL را به یک تابع در فایل View.py نگاشت کرده است ارسال می کتد،تابع متناظر با درخواست در فایل Views.py انتخاب کرده و داده های مورد نظر را از فایل Models.py دریافت می کند و قالب صفحه مورد نطر را نیز از پوشه Template دریافت کرده و در نهابت فایل HTml را تولید وبرای کاربر سایت ارسال(Response) می کند. همین وبس !!!!!!